Two recent cloud outages from Microsoft Azure and Amazon Web Services caused some severe loss of service for millions of users.
In this article, we’ll analyse what happened in both instances and open the debate on contingency plans.
On May 24, 2023, a prominent Microsoft Azure outage occurred in the South Brazil Region. The outage lasted over 10 hours and was caused by a typo in the code that deleted 17 production databases. Microsoft has since apologised for the outage and issued a full post-mortem, sharing details about the investigation and how the typo was made. The company has also promised to roll out Azure Resource Manager Locks to its critical resources to prevent future accidental deletions.
The typo occurred during a code base upgrade that was part of Sprint 222. The upgrade was intended to add a new feature to Azure DevOps, but the typo caused the code to delete the 17 production databases instead. The outage was detected within 20 minutes, but the root cause was not identified until almost four hours later. This delay was partly because customers could not restore Azure SQL Servers, as well as backup redundancy complications and a “complex set of issues with [Microsoft’s] web servers.”
Microsoft has since rolled out a fix for the typo and restored all the affected databases. The company has also apologised for the outage and has promised to take steps to prevent future incidents. These steps include rolling out Azure Resource Manager Locks to its critical resources, preventing users from accidentally deleting important data.
AWS Outage Takes Down Millions of Customers
On June 17, 2023, Amazon Web Services (AWS) experienced a major outage that affected millions of customers worldwide. The outage was caused by an issue with the Lambda serverless service, which is used by a wide range of businesses and organisations.
As a result of the outage, many popular websites and applications were unavailable, including Delta Airlines, Burger King, and Slack. The outage also caused disruptions for businesses that use AWS for critical services, such as customer support and financial transactions.
AWS engineers worked to fix the issue and restore service, and the outage was eventually resolved after several hours. However, the incident highlights the importance of having a backup plan in case of a cloud outage.
Here are some of the key takeaways from the AWS outage:
• Cloud outages can happen to any provider, so it’s essential to have a backup plan in place.
• Businesses that rely on cloud services should clearly understand their dependencies and how they would be affected by an outage.
• Cloud providers should be transparent about outages and provide clear communication to customers.
In both cases, the businesses affected could not have prevented the outages, so were their business continuity plans (BCP) effective?
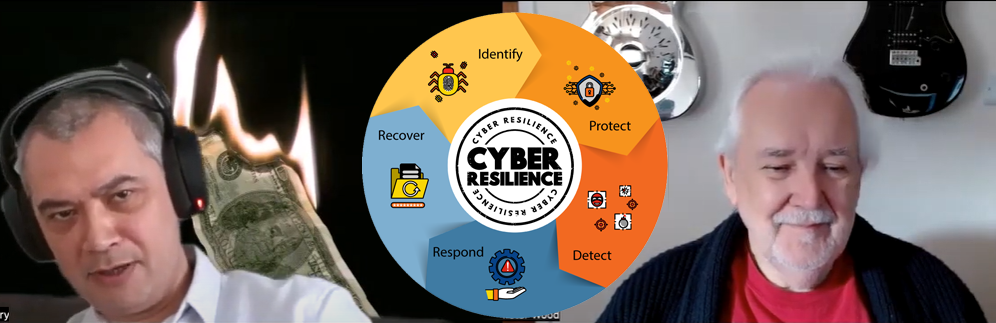
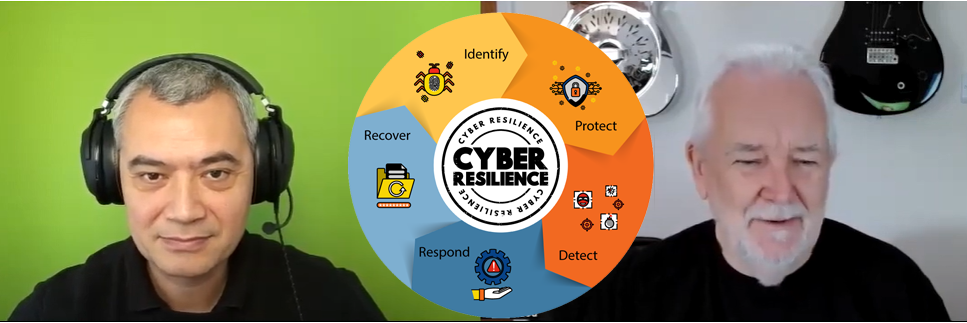
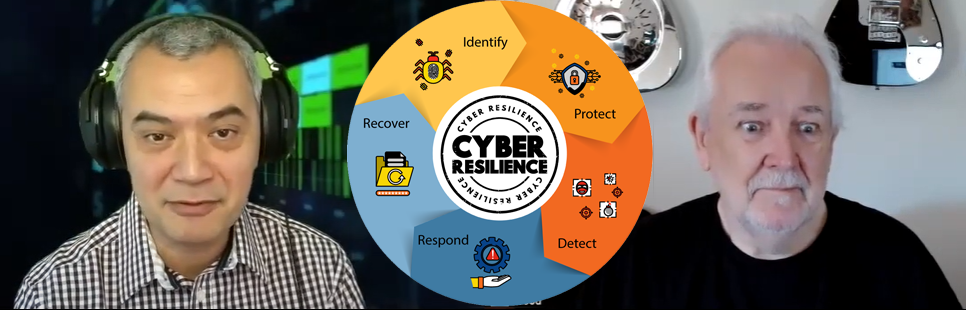
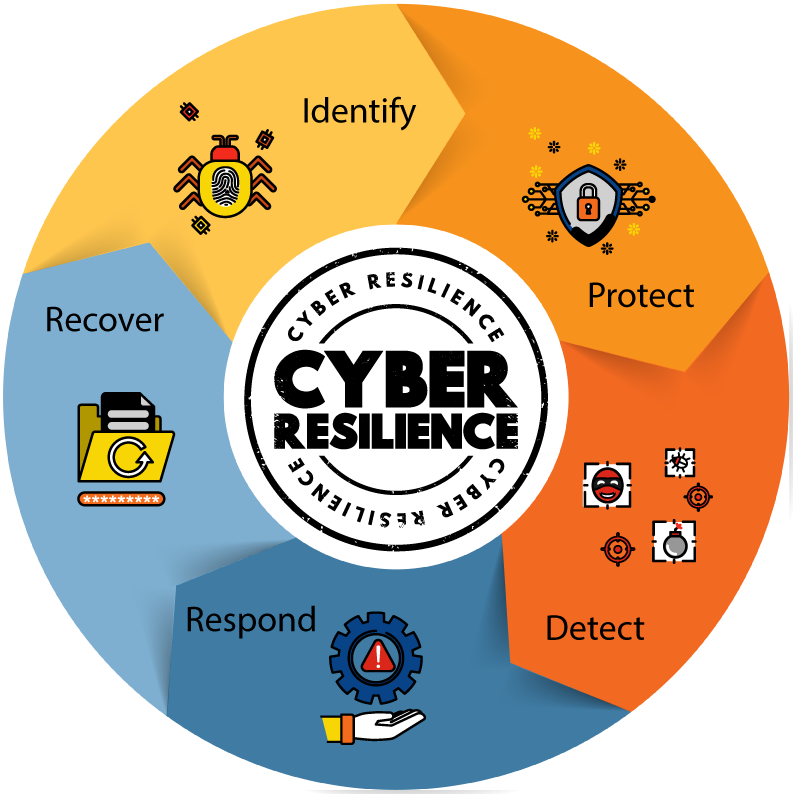
Having a BCP is an essential element for any business. Testing your BCP is also crucial to ensure your teams can implement these plans effectively and in a timely manner.
Organisations rarely consider red-teaming the emergency measures that should keep your business running. Contact us to help.